Blog
Dated: Jan 19, 2021
I cut my programming teeth at Le Wagon, where the bulk of coding time is spent on Ruby. I’ve also started in the Masters in Computer and Information Technology program at Penn, where the teaching languages are Python and Java. Naturally, it’s been a trip taking my Ruby cap off and putting a Python hat on. The Python hat isn’t too comfortable yet, but I’m sure it’ll break in as I get more Python under my fingers.
As I work more and more with Python, I’ve been putting together a mental cheatsheet for “translating” Ruby to Python, and it’s time for me to take the cheatsheet out of my brain and put it into writing. I know I’m not the only programmer who has moved from Ruby to Python, so I hope others will find this useful. (But hey, even if nobody else finds it useful, it’s helpful for me to put this in writing!)
Some basic stuff first
Integer and float division in Ruby:
5 / 2 #=> returns 2
5 / 2.0 #=> returns 2.5
Integer and float division in Python:
5 / 2 #=> returns 2.5
5 // 2 #=> returns 2
String interpolation in Ruby:
planet = 'world'
puts "Hello #{planet}!" #=> prints "Hello world!"
Formatted strings in Python:
planet = 'world'
print(f'Hello {planet}!') #=> prints "Hello world!"
String manipulation in Ruby and Python
Split a string into an array using a separator
Also known in PHP as explode(), still my favourite name for this operation.
Ruby:
'abracadabra'.split('a')
# returns ['', 'br', 'c', 'd', 'br']
Python:
'abracadabra'.split('a')
# returns ['', 'br', 'c', 'd', 'br', '']
Split a string on whitespace
Ruby:
'the quick brown fox'.split
# returns ['the', 'quick', 'brown', 'fox']
Python:
'the quick brown fox'.split()
# returns ['the', 'quick', 'brown', 'fox']
So far, so good.
Split a string using a regular expression
Ruby:
'a1b12c123d1234'.split(/\d+/)
# returns ['a', 'b', 'c', 'd']
You’ll probably be using Ruby’s built-in Regexp methods for complex operations involving regular expressions, but for splits on a simple regex, the String#split method works just fine.
In Python, regular expression operations require the re module:
import re
re.split(r'\d+', 'a1b12c123d1234')
# returns ['a', 'b', 'c', 'd', '']
Join array/list elements into a string
Also known in PHP as implode(), still my favourite name for this operation.
Ruby:
['the', 'quick', 'brown', 'fox'].join(' ')
# returns 'the quick brown fox'
Python:
' '.join(['the', 'quick', 'brown', 'fox'])
# returns 'the quick brown fox'
🤯
In Ruby, join is a method called on an array taking a string as an argument. In Python, join is a method called on a string taking a list (array) as an argument.
Enumerable patterns and list comprehension
Quickly generate an array from a range
Ruby:
array = (1..5).to_a
# array = [1, 2, 3, 4, 5]
The literal “translation” of this in Python is:
array = list(range(1, 6))
# array = [1, 2, 3, 4, 5]
However, to be a true Pythonista, you must use list comprehension wherever list comprehension can be used:
array = [i for i in range(1, 6)]
# array = [1, 2, 3, 4, 5]
Apply the same operation to all elements of an array
Ruby:
array = (1..5).to_a
squares = array.map { |i| i**2 }
# squares = [1, 4, 9, 16, 25]
Again, you can do this using a combination of list() and map() in Python:
array = [i for i in range(1, 6)]
squares = list(map(lambda i: i**2, array))
# squares = [1, 4, 9, 16, 25]
Yuck. Instead, use list comprehension:
array = [i for i in range(1, 6)]
squares = [i**2 for i in array]
# squares = [1, 4, 9, 16, 25]
Iterate over an array/a list with indices
Ruby:
array = ['Alice', 'Bob', 'Charlie']
array.each_with_index do |element, index|
puts "Index #{index}: #{element}"
end
# prints the following:
# Index 0: Alice
# Index 1: Bob
# Index 2: Charlie
Python:
list = ['Alice', 'Bob', 'Charlie']
for (index, element) in enumerate(list):
print(f'Index {index}: {element}')
# prints the following:
# Index 0: Alice
# Index 1: Bob
# Index 2: Charlie
Iterate over a hash/a dictionary
Ruby:
hash = { 'Alice': 9, 'Bob': 11, 'Charlie': 14 }
hash.each { |key, value| puts "#{key}: #{value}" }
# prints the following:
# Alice: 9
# Bob: 11
# Charlie: 14
Python:
dict = { 'Alice': 9, 'Bob': 11, 'Charlie': 14 }
for key, value in dict.items():
print(f'{key}: {value}')
# prints the following:
# Alice: 9
# Bob: 11
# Charlie: 14
Let’s take a step back and see what happens if you iterate over dict instead of dict.items(). In that case, the for loop will iterate over the keys only :
dict = { 'Alice': 9, 'Bob': 11, 'Charlie': 14 }
for i in dict:
print(i)
# prints the following:
# Alice
# Bob
# Charlie
You can still access the values using the key, of course:
dict = { 'Alice': 9, 'Bob': 11, 'Charlie': 14 }
for i in dict:
print(f'{i}: {dict[i]}')
# prints the following:
# Alice: 9
# Bob: 11
# Charlie: 14
Iterating over a hash in Ruby, on the other hand, always returns an array of two elements per iteration, with the first element being the key and the second element being the value:
hash = { 'Alice': 9, 'Bob': 11, 'Charlie': 14 }
hash.each do |i|
pp i
puts "#{i[0]}: #{i[1]}"
end
# prints the following:
# [:Alice, 9]
# Alice: 9
# [:Bob, 11]
# Bob: 11
# [:Charlie, 14]
# Charlie: 14
With dict.items() in Python, what’s really happening is that dict.items() is returning a tuple of two elements per iteration, with the first element being the key and the second element being the value:
dict = { 'Alice': 9, 'Bob': 11, 'Charlie': 14 }
for i in dict.items():
print(i)
print(f'{i[0]}: {i[1]}')
# prints the following:
# ('Alice', 9)
# Alice: 9
# ('Bob', 11)
# Bob: 11
# ('Charlie', 14)
# Charlie: 14
Keyword arguments / last argument hash
I’m not touching that hot potato.
Dated: Dec 31, 2020
In the beginning were zeroes and ones, and the zeroes and ones were with Boolean operators, and the zeroes and ones and Boolean operators were two-element Boolean algebra. All computation was made through Boolean algebra, and without Boolean algebra was not any computation made that was made. There is only so far I can take this strained analogy, before I start comparing Leibniz with John the Baptist.
Most of our interactions with computers these days happen at a very high level, in the sense that we don’t have to think too much about how a computer works. Our mental model of computation can be fairly abstract: I press a key on my keyboard, and the corresponding letter appears on my monitor. I drag a file on my desktop into a folder in my dock, and the file moves into the folder. I don’t have to think about how the switch under my left mouse button closes a circuit, how the mouse sends a signal to the operating system, how the operating system keeps track of the cursor’s position on the screen, or how the operating system knows which part of the disk drive to look for my file — I don’t have to think about any of that.
Web developers live in a world one level lower than most end users. We don’t have to live as close to the metal as developers working on embedded systems or operating systems, but we do have to understand how computers manipulate data. Fundamentally, all computers do is accept an input, do stuff to that input, and produce an output. (This is not all of computing, of course — the craft of computing includes considerations like algorithmic efficiency, systems architecture, information security, and much more besides.) Different types of developers might work with different types of inputs or outputs, but at the end of the day, whether your input is a rotary dial, a webcam image or a user’s keystrokes, that’s all we are doing. We take inputs, manipulate them, and return an output to the user.
Turtles All The Way Down
How close to the metal can we get? Obviously, when you get to the level of thinking about what’s inside the processor itself, you’re living in the world of logic gates and ones and zeroes. If you’re curious about what it really means when a computer runs on ones and zeros, there are two videos that I really like and recommend:
Carrie Anne Philbin of Crash Course Computer Science talks about how transistors can be used to perform Boolean operations.
Matt Parker of Stand-Up Maths and Numberphile builds a binary calculator by constructing logic gates out of dominoes.
How does understanding binary addition at the level of a circuit help us to think about computation? This is where abstraction comes in.
The Abstraction Layer Cake
Think about when you first learned to ride a bicycle. Your instructor (a parent, a relative, a teacher) told you to keep your hands on the brakes at all times. They showed you how to mount the bike and lean it to the right, then to spin the crank on the left side into position. They held your handlebars or your saddle as they told you to push down on the pedal with your left foot, and push off the ground with your right. Then they yelled at you to put your right foot on the pedal as it came up, and to look ahead, not down, look ahead! Keep your head up and pedal! Now you’re riding a bike.
If you bike regularly, you have all of this in muscle memory. Most of the time, you don’t have to remember to put your hands on the brakes, or to position the crank before you push off. When your riding buddy says “let’s go”, all of this happens all at once: the details of what it takes to ride a bicycle from a standing start have been abstracted away in your brain.
Learning to write is another instructive example. A child first has to develop gross motor skills. How do I pick up a pencil? How do I move it around? Then the fine motor skills: how do I control the movement of a pencil on paper? After that comes learning the alphabet: how do I write the letter a, b, c? At some point, the child graduates from letters to words, then from words to sentences, then from sentences to paragraphs, then from paragraphs to essays. When a student has reached the essay-writing stage, they no longer have to think about what their hands are doing to produce shapes on paper. The writing of letters and words has become abstract.
This is what happens with computers as well. When you are working with logic gates, all you have are NOT, AND and OR gates. These gates take one or two inputs, and produce one output. Out of these three gates, you can create a XOR gate. With these four gates and some way to store bits in memory, you can do math, represent letters and numbers, or store a pixel’s colour information. Crash Course Computer Science has an excellent video about how you can use bits to build primitive data types like integers, floats and chars.
Now we’re starting to approach a level of abstraction that most web developers recognise. I don’t know how C implements an integer exactly, but I know how to add integers together in C. I don’t know how JavaScript allocates memory for strings, but I know how to manipulate a string in JS. I don’t know which part of the spinning platter my text file is stored on, but Ruby’s Core Library has a File class that handles those details for me (and Ruby implements that File class using C, and…)
Peeling Apart The Layers
I can’t speak for other developers, but here’s what I’m usually thinking about when I’m working on a problem.
If I know what the input and output types are, then there are three questions I’m trying to answer:
- How is the input information represented?
- What information in the input do I care about?
- How do I manipulate this information into the type I need?
If I’m building a simple command-line application that asks the user for two numbers and adds them together, the answers might look like this:
- I have two inputs and they are both strings.
- I care about the numerical information that the strings contain.
- I can probably typecast the strings into integers or floats, then add them together.
If I’m doing something a little more complex, like reading monthly sales data from a CSV file and totalling up sales for the year, the answers might look like this instead:
- I have a CSV file, which the parser will parse into an array of arrays. Each element in each nested array is a string.
- I need the number that’s inside the last element of each array.
- I can use a reduce function to sum the last elements of each array. When iterating through the arrays, I need to make sure that the last element of each array is typecast into a float before adding it to the accumulator.
I want to dwell on that last point a little bit. The reduce function was hard for me to grasp intuitively as a student, and I’ve found it to be challenging to explain to students as a TA. What was helpful for me was reading the documentation for reduce carefully and working through it step by step — in effect, I dropped down one layer of abstraction until I felt comfortable enough to return to the higher level of abstraction. It’s like doing long division or differentiation by hand, until you feel comfortable enough with the mechanics of it to use a calculator. If you use a calculator and get an unexpected result, do it by hand, and see how your mental model diverges from the implementation of the abstraction.
The Law of Leaky Abstractions
In JavaScript, the largest integer that the Number type can store safely is 253-1, or 9,007,199,254,740,991.
console.log(9007199254740992 + 1);
// prints 9007199254740992
Why is that? The JavaScript Number type is a 64-bit floating point number that conforms to the IEEE 754 standard. That means that JavaScript uses 64 bits to store numbers in the form m times 2n. One bit is dedicated to the sign (positive or negative), 11 bits are dedicated to the exponent n, and the remaining 52 bits are dedicated to the mantissa, or the significand, m. That means that the mantissa m can never be larger than 253-1. (Bonus question: Where does the extra bit come from?) If you want to store an integer larger than 253-1 as a number in JavaScript, you can try — it’s just that JavaScript cannot store integers larger than 253-1 with precision.
If you really want to peek under the hood, you can check out this decimal to binary 64-bit floating point converter. This converter walks you through each step of converting a decimal number to a binary 64-bit float, and shows you the steps where you start to lose precision. I highly recommend trying this with the numbers 9007199254740991, 9007199254740992 and 9007199254740993, so you can see why JavaScript can store integers up to 9,007,199,254,740,991 but not one bit more.
This is a case of a leaky abstraction. A JavaScript developer typically does not need to think about how JavaScript represents integers in bits. For the overwhelming majority of use cases, JavaScript handles integer arithmetic just fine. However, when the abstraction leaks, when the abstraction doesn’t behave how we expect it to behave, that’s when the ability to drop down through the layers of abstraction and think about the moving parts one level down (or several, if need be) is critical.
Whatever Goes Down Should Also Come Up
It’s 2020, and developers spend far more time learning frameworks than programming languages. Frameworks are a layer of abstraction on top of programming languages, and most of us think and work at that high level of abstraction, dropping down to lower levels of abstraction as needed to debug problems. As a junior-level developer, that’s probably where I spend the most time and how I learn most of what I know.
Another thing I do to sharpen my skills is solve katas on Codewars and Hackerrank. Of course, just thinking through problems and writing code that passes the tests is a great way to learn and grow as a programmer. However, the biggest benefit of doing katas on these platforms is that I get to see how other programmers approach the problem. I’ve often painstakingly worked my way through a problem in many lines of code, only find that more experienced programmers know of a built-in method or library that does the same thing in just a few lines.
For example, take a look at this portion of code I wrote for this kata on Codewars:
numbers = (1000..nmax).to_a.select do |number|
number_str = number.to_s
number_digits = number_str.length
(number_digits - 3).times do |first_index|
four_digits = number_str[first_index, 4].chars.map { |char| char.to_i }.sum
break false unless four_digits <= maxsm
true
end
end
Compare this with the portion of the top-rated solution that does the same thing:
arr = (1000..nmax).to_a.select{ |n| n.to_s.chars.map(&:to_i).each_cons(4).to_a.map{ |k| k.reduce(:+) }.max <= maxsm }
Why is my solution so much more laboured than the top-rated solution? Until I saw other programmers’ solutions, I had no idea that the each_cons method even existed, so I wrote my own loops to achieve the same result. Fortunately, someone smarter and wiser than I am has realised that these mechanics can be abstracted away, and already written a method to do it.
(Note on 2023-12-28, with the benefit of three years of experience: Today, I would not hold up this snippet as a shining example of good code. Good for code golf, not good for your co-workers.)
I’ve learnt a lot about Ruby and JavaScript this way: this is how I learnt about the existence of the Prime singleton class in Ruby, and it’s how I started to get the hang of reduce.
Thinking about computation doesn’t only involve being able to drill down into the details, but also being able to move up a level of abstraction to move faster and think more efficiently (and more abstractly) when it makes sense to do so. This also helps to keep code DRY and more easily maintainable, by allowing your fellow programmers to work at a higher level of abstraction instead of being bogged down in your implementation details.
Implications for Novice Developers
There’s plenty of advice out there for junior developers, especially in the realm of how to break out of tutorial hell, where you can only do something by following a tutorial but you don’t know why it works — or worse, when you can’t do something even when you follow the tutorial and you don’t know why it doesn’t work.
My humble addition to this pool of advice is this: get comfortable moving between different layers of abstraction. Learn to love working in the weeds, learn what your tools are doing for you so that you can use them to the most efficient extent possible, and start getting a sense of what the right level of abstraction for each problem should be. This way, you’ll be able to break down problems into just the right-sized chunks for you to tackle with the set of tools you have, and you’ll slowly expand your toolbox to work with the layers of abstraction both above and below where you spend most of your time thinking about computation.
Dated: Nov 22, 2020
Now that Heroku no longer has a free tier, the Macrotery demo is no longer online. You’ll have to review the repo, the write-up and the screenshots.
About Macrotery
Macrotery is a project that originated as a final project at Le Wagon batch #454 (Singapore), by Allen Chung (allenchungtw), Stephen Das (steevesd), Zack Xu (konfs), and myself. The idea is simple: what if you could search for food at eateries near you based on their protein, carbohydrate and fat content?
Many people track the macros of the food they eat in order to meet their health and fitness goals. Those who are looking to lose weight might aim to keep their overall caloric intake low. Bodybuilders generally want high protein, low fat meals. Endurance athletes fuel their training with lots of carbohydrates. Unfortunately, this makes it difficult for individuals tracking their macros to eat out, since it can be hard to find food that fits their macro targets in eateries.
Macrotery is a minimum viable product / proof of concept aimed at solving this problem. Users enter their macro targets, and can then search for meals at nearby eateries that match their macro targets.
Macrotery Redux
After our Le Wagon bootcamp ended, I decided I wanted to continue working on Macrotery for a little bit more, so I forked the Github repository and continued working on it as Macrotery Redux. I had two main goals with the Redux version:
- Completing the unhappy path: all the work on Macrotery was directed at completing the happy path for our bootcamp demo. There were multiple niggling bugs and UI issues that would have resulted in a sub-par user experience for a real user, which I wanted to reduce.
- Fixing layout issues: Macrotery is a Progressive Web App (PWA), meaning it can be used on desktops, laptops, tablets and mobile phones. However, our bootcamp demo was optimised for mobile only, and was barely usable on any device larger than a mobile phone. Macrotery Redux is not truly responsive in that it does not make use of most of the screen space available on larger devices, but I wanted to at least make it look more presentable on non-mobile screens.
Managing state in StimulusJS
Le Wagon’s bootcamp does not delve deep into front-end frameworks, because Le Wagon does not consider it to be possible to learn properly both vanilla JavaScript and and heavyweight front-end frameworks such as React, Angular or Vue within the compressed timeframe of the bootcamp.
A caveat: I have played around with React, but am not comfortable enough with it yet. I don’t truly have a sense of what React (or any other front-end framework other than StimulusJS) is capable of, and everything I say below should be read with this caveat in mind.
Since Le Wagon has such an intense Rails focus, there are two frameworks that we did use: Turbolinks and StimulusJS. Both are sufficiently lightweight that they do not require the paradigm shift of React, Angular or the like, and can be quickly be learnt within hours by anyone who knows vanilla JavaScript. This replicates Basecamp’s own stack, and you can read about the logic behind their choice in The Origin of Stimulus.
How do you manage state in StimulusJS? Here’s the Stimulus handbook on managing state:
Most contemporary frameworks encourage you to keep state in JavaScript at all times. They treat the DOM as a write-only rendering target, reconciled by client-side templates consuming JSON from the server.
Stimulus takes a different approach. A Stimulus application’s state lives as attributes in the DOM; controllers themselves are largely stateless.
Hmm. I can’t say I know how much easier or more difficult this would be with React, especially with a state container like Redux or Flux. Stimulus’s approach to state essentially means that whatever state you need to store needs to live somewhere in the DOM, or be otherwise retrievable without the use of a state container.
As we worked on Macrotery, we found that we needed to manage state in two of our key features:
- Remembering the user’s selected macros
- Remembering the user’s cart
I’ll talk about my experience with the former, since that’s the one that I implemented (the latter was implemented by my teammate Zack).
The problem
When the user is searching for a meal, they have the option of selecting one of their preset macros, or entering custom macros on the fly. When they then click through to a specific eatery to order, the order page needs to know what their macros are, so that the app can warn them if they exceed their macros.
The search happens in the /dishes page (dishes#index), and the macros that the user selects have to be passed on to the /eateries/:id page (eateries#show). The quickest way to do this is to append a query string whenever the user clicks through to an eatery’s page:
// a method inside a StimulusJS Controller instance
appendMacros(e) {
e.preventDefault();
const path = e.currentTarget.href;
// proteinTarget, carbsTarget and fatsTarget are essentially query selectors
// defined at the top of the Stimulus controller
const protein = this.proteinTarget.value;
const carbs = this.carbsTarget.value;
const fats = this.fatsTarget.value;
const url = `${path}?protein=${protein}&carbs=${carbs}&fats=${fats}`;
Turbolinks.visit(url);
}
<% # a StimulusJS action attached to a link to an eatery inside a Rails partial %>
<%= link_to eatery_path(dish.eatery), data: { action: 'click->macros#appendMacros' } do %>
<% # bunch of HTML here %>
<% end %>
This is implemented using Stimulus and Rails helpers, but it should be fairly easy to understand, almost pseudo-code-ish, for anybody familiar with JavaScript and Ruby. Stimulus creates a “click” event listener that’s bound to the eatery link. Whenever the user clicks through to an eatery page, the click is intercepted by the appendMacros function, where it reads the protein, carbs and fats values that the user carried out the search with. The function then appends the three variables as a query string to the URL that the user was going to visit in the first place, and hands the new URL to Turbolinks to handle.
The purpose of passing this information over to the /eateries/:id page is to warn the user if they have exceeded their desired macros. We discussed how to do this given the limited real estate of a mobile screen, and settled on using a collapse that could be displayed or hidden by clicking on a warning icon:
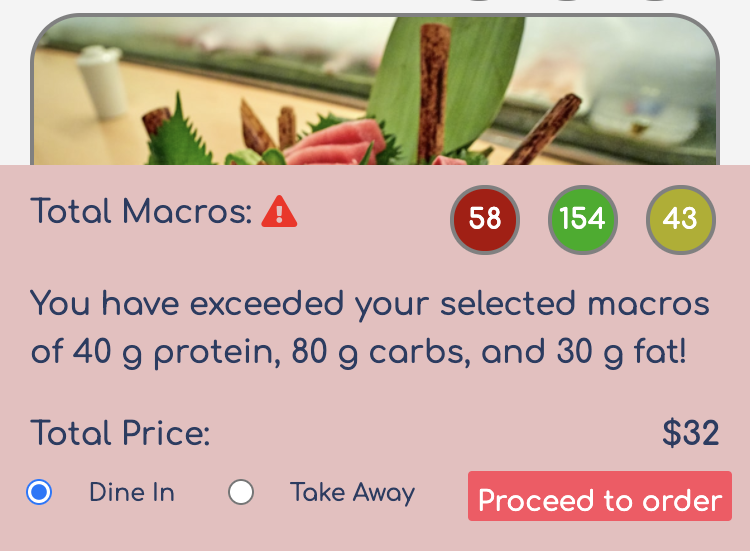
Remember, in StimulusJS, the state lives in the DOM. This made the warning message a convenient place to store the state of the user’s macros:
class EateriesController < ApplicationController
def show
@protein = params[:protein]
@carbs = params[:carbs]
@fats = params[:fats]
end
end
<% # eateries#show view %>
<% if @fats && @carbs && @protein %>
<div class="collapse py-3" id="your-macros" data-target="total.yourMacros">
You have exceeded your selected macros of
<span data-target="total.userProtein"><%=@protein%></span> g protein,
<span data-target="total.userCarbs"><%=@carbs%></span> g carbs,
and <span data-target="total.userFats"><%=@fats%></span> g fat!
</div>
<% end %>
The collapse is not visible by default, and the warning icon serving as the collapse handler is only visible when the user has exceeded their macros. When the page loads and the Stimulus controller is connected, Stimulus reads the protein, carbs and fats from the warning message.
To be honest, I had the much easier assignment: I really only needed to pass three values from one page to the next, and doing this in StimulusJS is not significantly different from doing it in vanilla JS. Zack had the task of implementing state management for the order cart using Stimulus, and that is a much more difficult task.
Within the constraints of the bootcamp, I think we did a decent enough job. Of course, now I’d like to learn React and implement a shopping cart using React and Redux, to get a better feel for what state management is like in other JavaScript frameworks.
Takeaway
Macrotery was, for us, an exercise in building a product using the tech skills we’d built up over the course of the preceding nine weeks, and a great way to showcase what we were capable of building as a team. However, Macrotery as a product is not a tech product.
I’ve been asked if I want to continue working on Macrotery beyond what I’ve done individually on Macrotery Redux, and my answer is no: I like code, and I like building stuff, but I want to build things that other people can use. For a product like Macrotery to be successful, it needs the infrastructure of an entire business around it: a partnerships team to bring eateries onto the platform (with the added difficulty of getting partners to input macros for every single item on their menu), sales and marketing teams to drive user adoption, business strategists to figure out where such a product could carve a niche in a market that already includes Deliveroo, Foodora and Grab, and an executive team to steer the ship.
If such a company existed, I would certainly consider joining it as a software developer, because I’d love to have a product like Macrotery as a user. But since it does not exist and neither I nor my teammates are interested in turning it into a business, it makes very little sense to me to continue working on Macrotery. I’d rather be focusing on software that can have a real impact on real users right now.